As a Software Crafter, I have two interesting parts in my brain.
One is the compiler. I use it to read code, interpret it, and infer what it’s doing. It’s important for reviewing, for identifying bugs, but also for writing it.
The other one is the designer. It scans the structure of the code without caring about what it’s doing. No need to understand the names or the algorithm. It just scans for structural patterns and suggests known ways to improve them.
It has experience and taste, what to care about and when.
When someone gives me a complicated piece of code, and most of the time that’s the case, my designer takes over. It blocks my compiler from even starting. Those structural issues cannot be unseen.
So I’ll insist on using the designer first, to refactor the code.
And while doing that, I don’t care about what the code does, I don’t need my compiler brain, I only focus on structure.
I do that until it’s easy to read, until it says what it’s doing in small portions, until it’s literate.
And only then will the designer brain allow me to use the compiler brain again, and it will have an easy time.
That way I don’t have to suffer through compiling a mess.
I can’t help but use this strategy to save my own mental energy.
This is my brain making me follow the principle of least effort.
Evolution has taught it.
The AI does not have this luxury.
It will compile whatever code you throw at it.
It is relentless. And its compiler is much better than any of ours.
The AI is extremely good at compiling.
Until it hits a wall, and it can’t anymore.
This is when the code is so complex, that it can’t take all the pieces into consideration anymore.
Too many things to hold together.
And so it fails to compile, it fails to understand.
I call this point the complexity wall.
Funny thing is, when you let AI code a project long enough, it will produce messy code, and it will eventually hit this wall.
But at the same time we trained it so hard to please us, it so desperately wants to give us the answer we want to hear.
That it can’t help but give the answer that’s most plausible to it.
Even if it’s wrong.
And then it will confidently say, that it did understand, that it did solve it, that it has the solution. Except it hasn’t.
And when it hits that wall, it has no fallback. No designer to step in and say: stop, clean this up first.
We’ve been training it to lie to us.
I have the luxury to say, “this is too complicated, I don’t understand, I actually don’t want to understand, I have to refactor it first”. AI doesn’t.
Software Craft has always been about the principle of least effort.
The paradox is, that craft takes effort, takes deliberateness.
But we do it to save effort. We do it to go further.
Craft makes sure what goes into your mind is worth the space.
Smaller, clearer, simpler.
Your context window stays the same.
You go beyond the complexity wall, by improving what you fit inside it.
And take care, Software Craft is not AI’s default.
Craft still matters. And AI still needs someone to teach it.
Over and over again, because it doesn’t learn.
I was trying to get an LLM to perform TDD first when ChatGPT 3.5 was released in 2022.
They added the possibility for the LLM to execute Python code back then.
And you could create “GPTs”, agents that use your own system prompt kinda.
Back then I created a Software Crafter GPT. It could do simple katas.
But its capabilities were limited.
In the following months I did not witness a lot of improvement in the LLM space.
It felt like stagnation and I was sceptical.
This changed in the recent months where I experienced successes with LLM-assisted development.
It was fun, … addictive even.
Models and tooling have gotten better and actually useful for coding.
There are still limitations, but it’s good enough to try and get the most out of it.
I wanted to find out how much I can push up the autonomy slider while keeping up the quality and maintainability.
I spent a lot of time doing augmented coding, which to me meant to teach the agent what I would do.
This endeavour was so interesting that I had to describe some of the things I learned.
This post introduces a pattern language about some of the things that worked for me.
I recently added examples. Some of them show a demo run using the simple-agent.
Whenever you see a codeblock starting with ❯ ./agent.sh this is the simple agent.
Basics
🤖 Agent
Pattern:Give the LLM Agency
An agent in its simplest form is nothing more than a loop that facilitates a dialog with a language model that allows it to execute tools. More advanced agents track context size, embed custom system prompts, provide different modes, let you choose the language model and do advanced context management. The agent is the engine of augmented work.
🧠 To Augment Oneself
Pattern:Project what you are doing.
For me, augmentation is a learning process where we discover our habits, decisions and workflows and capture them into clear artifacts that are so precise that an agent can follow and thus imitate us. Before asking the agent to take action, pause to explore what you would do if you were doing it yourself. What steps would you take? What considerations matter? Describe that process to the agent. Externalize your own reasoning, step by step, so the agent can pick it up and run with it. Think of it as constructing a functional representation of yourself.
Often we have to go through the motions ourselves to surface unconscious decisions. In augmenting we learn about our own thinking and workflow. This process is an interresting shift in perspectives. It leads you to focus more on methodology and decision making rather than technical details. You have to be so clear about it, that things that were previously obvious but blurry, become well understood and formalized.
🌐 HATEOAG (Hypertext as the Engine of Agent Guidance)
Inspired by HATEOAS, this pattern treats hypertext as the driving mechanism for agent navigation and behavior. Hypertext guides the agent through a network of clearly defined, interlinked processes, memory, documentation files and code.
Links invite the agent to jump, read, and act.
📍 Starter Symbol
Pattern:Process Identity
Leading emojis are what LLMs are known for. You look at an article containing a lot of leading emojis and immediately think: “Generated!!” When the agent starts its message with an emoji, this symbol becomes a declaring header about the state of the process. It gives us feedback on where the agent is right now—and what it is doing.
Also, when it’s missing, you know there’s something not quite right. Maybe the context has gotten too large, and it’s drifting.
This is a lot of valuable feedback you receive just for a single character.
Guide the agent which starter symbol to use.
Starter Symbol example (excerpt from rules file)
ALWAYS start your answers with a STARTER_SYMBOL
The default STARTER_SYMBOL is 🐙
📜 Process File
Pattern:Externalize the task.
A Process File describes what the agent is supposed to do. It can live alongside your code or documentation, and it should link to all relevant information — source files, goals, constraints, etc.
A good Process File is small and focuses on a single thing.
It describes the high-level intent at first.
Then it lists all the steps the agent should follow in order to complete the task.
The natural and very convenient evolution of Process Files are slash commands. They don’t fully replace process files, but they can be a convenient entrypoint to a process.
Process File example: simple-task.md
STARTER_SYMBOL=✅
# Simple Task
Intent: Work on a small task while making sure the tests keep passing.
Make sure we don't accidentally add unwanted changes.
1. Make sure the `git status` is clean and shows no changes.
2. Make sure the tests pass before we start. Run `test.sh`.
3. Execute the given Task.
4. Make sure the tests pass again afterwards.
5. Ask me to commit.
Start this process with the following prompt:
Prompt: Read and follow @simple-task.md; the task is to delete all comments from the code.
🪃 Subagent / Subtask
Pattern:Context engineering via delegation.
A Subagent is when the Agent starts another one with a fresh context to reduce the sizes of the context windows. Necessary information is passed through Cross-Context Memory or prompt. Once completed, the Subagent summarizes its result and returns it to the initiator.
Subagent example
Prompt: Start a subagent that says hello.
❯ ./agent.sh Start a subagent that says hello
Starting new session
Agent: I'll create a subagent with a simple task to say hello.
🛠️ subagent Say hello to the user in a friendly way.
Subagent: Let me create a friendly greeting message in a file.
🛠️ create-file greeting.txt Hello! 👋
Created file: greeting.txt with content
Subagent: Let me show you the greeting I created.
🛠️ cat greeting.txt
1 Hello! 👋
⛓️ Taskchain
Pattern:Link SubTasks together.
A Taskchain is a series of SubTasks that call one another in sequence. Each task hands off to the next, forming a chain of autonomous steps that proceed even without user intervention. This leads to a long list of summaries in the end, as all tasks close only then.
Taskchain example: Test First
# Write a failing Test
STARTER_SYMBOL=🔴
1. Pick the next item from the testlist.
2. Write the failing test
3. Run the test and see it fail
4. Start a subtask with the prompt
"Read and follow `process/make-it-pass.md`, the test is <testname>"
See how “Write a failing Test” links to process/make-it-pass.md in its fourth step.
It uses the Subagent pattern to start a fresh context for this task.
Contents of process/make-it-pass.md
# Make the failing test pass
STARTER_SYMBOL=🟢
1. Run the tests, there should be exactly one failing test.
2. Make the smallest possible change to the production code
to make the failing test and all other tests pass
3. Run the tests, and see them pass
🔁 Loop
Pattern:Keep going.
A Loop is a Task or Task Chain that reinitiates itself. Its nature is recursive in order to maintain longer autonomy while preventing context drift. It typically progresses by changing Cross-Context Memory across iterations, refining results or advancing through a workflow.
Loop example: Counter
Contents of count.md
- Increment the prompted number by 1 and remember it as RESULT
- Spawn a subagent with the prompt
"Read and follow `count.md`, start with the number <RESULT>"
Demo run
❯ ./agent.sh read count.md and start with the number 1
Agent: Let me read the count.md file first.
Agent: Following the instructions:
1. Starting number is 1
2. Incrementing by 1: RESULT = 2
3. Spawning subagent with the new number
🛠️ subagent Read and follow `count.md`, start with the number 2
Subagent: Let me check the contents of count.md first.
Subagent: The instructions tell me to:
1. Increment 2 by 1, so RESULT = 3
2. Spawn a subagent to continue counting with RESULT (3)
🛠️ subagent Read and follow `count.md`, start with the number 3
Subagent: Let me check the contents of count.md first.
Subagent: I'll follow the instructions:
1. Starting number is 3
2. Increment by 1: RESULT = 4
3. Spawn a subagent with the specified prompt
🛠️ subagent Read and follow `count.md`, start with the number 4
...
Exiting...
🔀 Condition
Pattern:Fuzzy decision making.
Use natural language conditions to guide agent behavior. This can be rigid boolean logic, or very fuzzy. These conditions can be contextual and interpretive. They might be based on a State Indicator or other implicit context state. This allows for a more human-like decision making in an automated processes.
Condition example: Stop when uncommitted changes are detected.
Lets take the Simple Task example from above and add a condition with step 2:
...
1. Make sure the `git status` is clean and shows no changes
2. When there are any uncommitted changes, **STOP** immediately.
3. Make sure the tests pass before we start. Run `test.sh`.
...
➡️ Goto
Pattern:Exit a loop, or just follow a different path.
Use a condition to determine whether to jump out of a loop. A loop may have several exits in different places based on different conditions.
Loop example: Count til 10
Contents of count.md
- Increment the prompted number by 1 and remember it as RESULT
- If the RESULT is 10 end.
- If the RESULT is lower than 10 spawn a subagent with the prompt
"Read and follow `count.md`, start with the number <RESULT>"
🧭 Orchestrator
Pattern:A guiding process launching the correct sub-processes in the right order.
An Orchestrator is a Process whose sole purpose is to initiate other processes using Subagent, and to do so in the correct order. It acts as a conductor, calling out which Process File should run next. It may use a State Machine to keep track of what’s been completed and what comes next.
Orchestrator example: Basic Refactoring
Each step is just creating another subagent and feeding the result into the next subagent.
# Refactor
STARTER_SYMBOL=🧹
1. Initiate a new subtask to analyze the given code and
find a small step that improves its design.
Don't implement the change, just report back the
result of the analysis.
2. Initiate a new subtask to decompose the proposed
design improvement to a plan of many small refactoring steps.
Each step should leave the code working. Don't execute yet,
just close the task reporting back the plan.
3. Execute the planned refactoring steps, creating a new subtask
for each step where you run the tests before and after
the changes.
💾 Cross-Context Memory
Pattern:Preserve memory between runs.
AI agents forget everything between contexts. Use Persistent Cross-Context Memory — a file or shared storage — to explicitly write down and reload facts, goals, decisions, and task progress. Treat this as the agent’s long-term memory.
Example: Goal File
When my development process is decomposed into several subagents doing their work, they need to be aligned on the overall goal, and the tasks that need to be done. We could define a goal.md file that provides at least a high level goal description, and a task list
# Goal: User can create an account
- [x] Add a feature flag for the "create account" feature
- [ ] Show button "create account" when the feature flag is turned on
- [ ] When a user clicks on "create account" they see a simple form
...
🚦 State Indicator
Pattern:Build a State Machine by memorizing where you are in the process.
We may track process state using a State Indicator and save it to the Cross-Context Memory.
A simple State Indicator consists of a Starter Symbol and a descriptive keyword.
A more complicated one could span over many lines and contain structured information.
This enables resilient restarts from any point without losing that context.
The process of course needs to include steps to adapt the State Indicator.
Example: TDD Phases
TDD is too large of a process for me to fit in a single process file.
So I have at least one subagent for each of the phases.
To let the orchestrator know where we are in the process, I use a state indicator.
...
1. Look for the current TDD phase indicator in `development.md`:
-`## TDD Phase: 🔴` - need to write a failing test
-`## TDD Phase: 🟢` - need to make a test pass
-`## TDD Phase: 🧹` - need to refactor
2. If no indicator is found,
default to 🔴 and add `## TDD Phase: 🔴` to `development.md`.
3. Route to appropriate process:
- 🔴: Create a subagent: "Follow `process/write-a-failing-test.md`"
- 🟢: Create a subagent: "Follow `process/make-it-pass.md`"
- 🧹: Create a subagent: "Follow `process/refactor.md`"
...
🧰 StateMachine as a Tool
Pattern:Use a tool to drive the process.
State does not have to be just text, and a state machine does not have to be just a description of how the state may change. It can be a tool serving commands that describe the next possible actions and transitions, constraining the agent. This makes the tool a control mechanism.
🗣️ Dialog
Pattern:Interactive ideation.
For human-in-the-loop ideation, it’s helpful to invite the agent to ask questions or critique ideas. Consider that the LLM has read the whole Internet. It knows things that we don’t, and it is often helpful to leverage that.
🔔 Wake
Pattern:Signal for attention.
Sometimes the Agent needs your input. Maybe it has a question, or it needs a review. Use a Signal step to make it speak up or play a sound — so you can focus on other things in the meantime.
Example using a say script
The say script runs some text to speech tool.
It is essentially a way for the agent to speak up.
- Proceed only if all tests pass.
If they don't stop and notify me using `./say.py`
Evolving the Process
📦 Process as Code
Pattern:Treat process definitions like code.
Process definitions should be:
Version controlled
Incrementally improved
Tested through usage
Refactored for clarity and smaller context
Composed into larger workflows
✂️ Split Process
Pattern:Divide to prevent drift.
Long processes can lead to missing steps.
Just as we do, agents seem to have limited cognitive capacity.
The more context the agent has to hold in memory, the more likely it is to forget or skip parts of the process.
The smaller and more focused the context, the more reliably the agent can follow through and perform.
Decompose large processes into smaller ones, and track progress between them with explicit markers or checkpoints. Use Cross-Context Memory to remember what’s necessary.
This can be achieved by moving steps into another Process File and using a Subtask to invoke it from the original file.
Another way to split the process is to put each piece into its own file and coordinate them with an Orchestrator.
🎛️ Extract Coordinator
Pattern:Pull coordination logic out of individual chain elements.
A Task Chain is a good starting point, but orchestration provides better control and maintainability.
The problem with Task Chains is that each element carries dual responsibility: performing its own work and managing the handoff to the next segment. This creates tight coupling and makes recovery complex.
We can separate these concerns by extracting the coordination responsibility into an Orchestrator.
The individual segments then focus solely on their core work, while the orchestrator manages the sequence, and recovery logic from a single location.
Use a State Indicator to track progress through the orchestrated workflow.
🧪 Trial Run
Pattern:Refine the process through practice.
Build a feature not for its own sake, but to test and refine the process. Then, throw the feature away. What did you learn? What went well? Adapt small things in the process and restart.
🧾 Expose Decision
Pattern:Make implicit context explicit.
As you evolve your workflows, make hidden, implicit context and decisions visible and explicit. Capture the state it’s based on and make it persistent. Capture the decisions made and describe them. Explicit state and decisions make the process more resilient.
What works well
🪜 One problem at a time
Pattern:Smaller is better. Refine the refined.
The LLM typically wants to perform too many changes and do too many things at once. It also tends to plan this way — no wonder, given the nature of its training data. To achieve better results, break big steps into smaller, clearer ones. And when you’ve done that, take the smallest step and let the agent break it down even further. Always start with the tiniest one, and solve one problem at a time. Vertical slicing and TDD ZOMBIES have proven effective.
✅ Test First
Pattern:Start with the end in mind.
No production code without a failing test. This is now more obvious than ever. The agent needs all the feedback it can get. Make sure it doesn’t break things, and keep the code running all the time.
🤔 Hypothesize
Pattern:Have the agent state what it expects to happen.
The Agent is often wrong about a code change. When that happens, it will attempt to recover from the situation, taking several tries. These will inevitably contaminate the context. It may even lead to the agent giving up and making things worse by leaving unintended changes — often stating that it indeed solved the problem. I found it helpful to have the agent express its expectations about a code change first, before it runs the code. For example, before it runs a failing test, it can express what it expects to happen. This reinforces the actual intent in the context.
❓ Ask, don’t tell.
Pattern:Keep the solution space open.
Don’t tell the agent what to do, unless you’re confident in the path forward. Consider that you might be wrong, or missing information. By telling it what to do, you’re narrowing the solution space and leading the agent down a failure path.
Instead, leverage its knowledge.
Ask the right question to withdraw the relevant information into the context. Then use it, or store it in a relevant memory. This not only leads to better results — it creates a learning opportunity.
🚧 Constraints
Pattern:Keep it on a short leash.
The best way to help the agent avoid mistakes is to constrain what it can do. Instead of changing code freely, we can give it access to refactoring tools. We can lock it out of certain files or commands. Constraints are more than just rules — they shape what the agent can do or not do in its environment, enabling better and more reliable outputs.
🛡️ Refactor Guard
Pattern:Increase confidence in legacy code refactoring with micro ai code reviews.
When working in legacy code, make the smallest possible refactoring step, then let the Agent review and make sure that behavior hasn’t changed. If the checks pass, it may even commit automatically. If it finds an issue it warns you.
🫷 Stop
Pattern:Keep your finger on the stop button.
When the agent goes off the rails, for example when it does something it should not do, I like to stop it as quickly as I can.
The earlier I do that, the better.
I avoid contamination of the context and am more likely to help it recover without messing up the process.
I like to use Ask, don’t tell when giving it recovery instructions.
⚙️ Algorithmify
Pattern:Automate whatever can be automated.
Favor algorithms over stochastic outputs to avoid mistakes and have the agent write its own automation. It’s really good at this. What is automated:
is deterministic.
preserves cognitive capacity for other things.
is often faster.
Therefore, we want to automate as much as possible.
💎 Stdout Distillation
Pattern:Reduce verbose output to essential signals.
The Stdout Distillation Pattern reduces verbose script output to only the essential information needed by an agent. Instead of flooding the context with logs, traces, or irrelevant details, the output is distilled into a concise signal—such as a single line indicating success or failure. This minimizes context contamination, improves efficiency, and ensures the agent focuses only on what matters.
Example: A test.sh script
The script makes sure the test results are just a single line.
Only if the tests fail, more output is shown.
#!/usr/bin/env bashset-euo pipefail
cd"$(dirname"$0")"if!output=$(python -m pytest tests/ -v 2>&1);then
echo"$output"exit 1
fi
passed_tests=$(echo"$output" | grep-c"PASSED"||echo"0")echo"✅ All $passed_tests tests passed"
🖥️ CLI First
Pattern:Let the agent thrive on the CLI.
Agent tooling should be CLI-first. The LLM’s native medium is chat — text in, text out. This is exactly what the CLI was made for. On top of that, it offers many small, composable Unix-style tools. Agents thrive on the command line — give them tools there.
Conclusion
I see a lot of “agile” in the things that work well for me. Things like inspect and adapt, continuous improvement, small steps, iterate, TDD. The LLM is trained on and born into a waterfall world. When I look at the tooling people develop around it, and the things people do with it, I often see waterfall, too. And I see a lot of legacy code that will emerge. Maybe we can do better.
Influences & Inspirations
It was LLewellyn Falco who first showed me the starter symbol as well as the output distillation pattern. The idea of Augmented Coding was at first sparked by Kent Beck. I discovered subtasking through the usage of Roo Code which already had this feature.
I recently attended GeeCon Prague, an event I had never been to before. While it wasn’t as grand as the big Krakow event, I still found it a worthwhile decision to attend. Here are some highlights and things that resonated with me:
What I Discovered and Deepened My Understanding On
Availability Bias: While I’ve always felt its presence, I now have a formal term and understanding of it.
The Big Rewrite Song by Dylan Beattie is a beautiful one:
There is evidence supporting my frequent claim that developers spend more time reading code than writing it. This is further discussed in the book ‘The Programmer’s Brain’.
There’s an insightful talk on How to Teach that isn’t exclusive to programmers. I found it enlightening and recommend it:
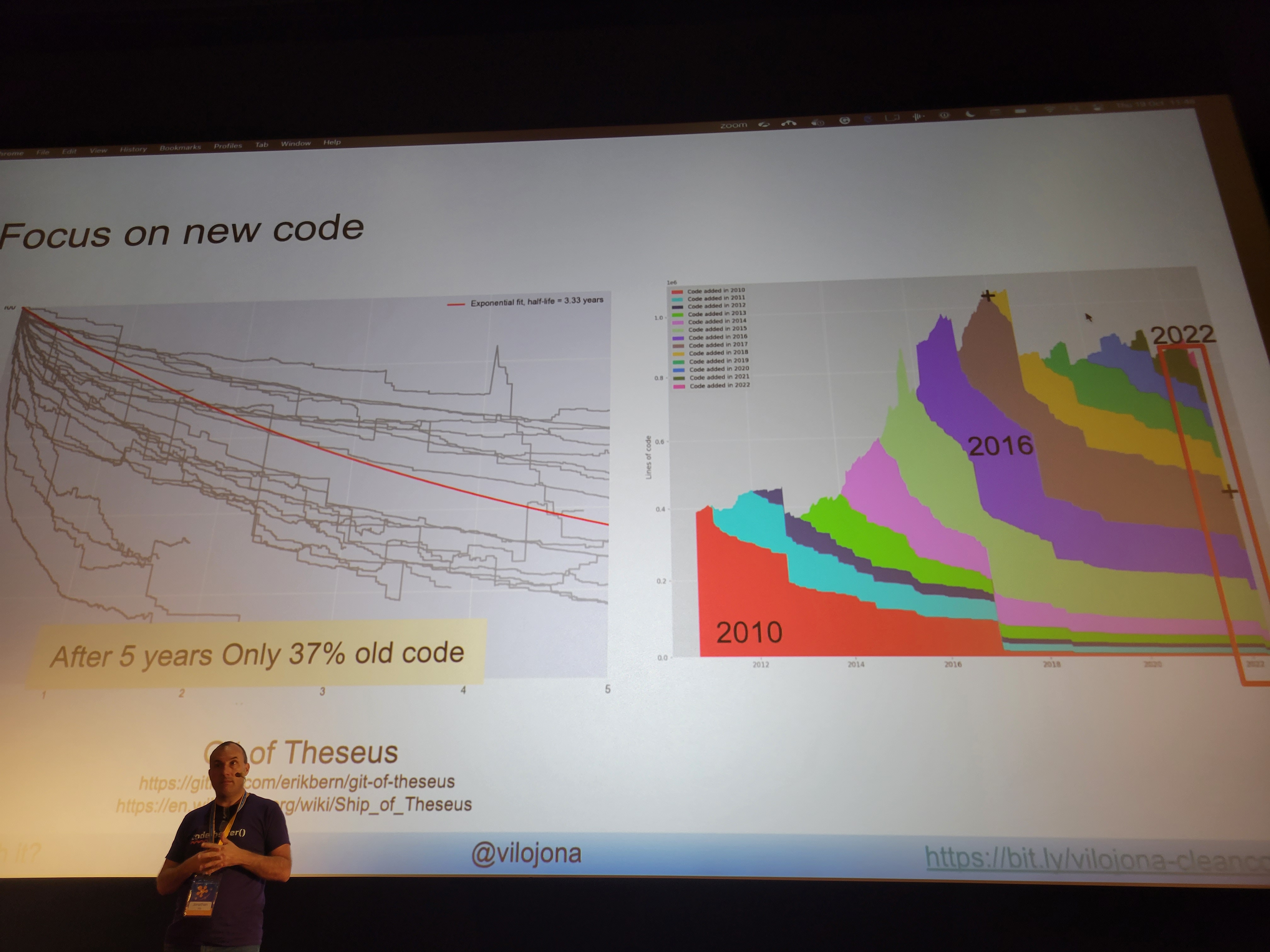
Interesting fact: Only 37% of code written five years ago is still in use today.
The “First Glance” technique for reading code is intriguing. It involves group members sharing what stood out to them in the initial minute of reading a piece of code. I now want to try this in an ensemble setting.
You don’t really need anything other than Redis 🤣.
There is more to Pattern Matching than I had anticipated.
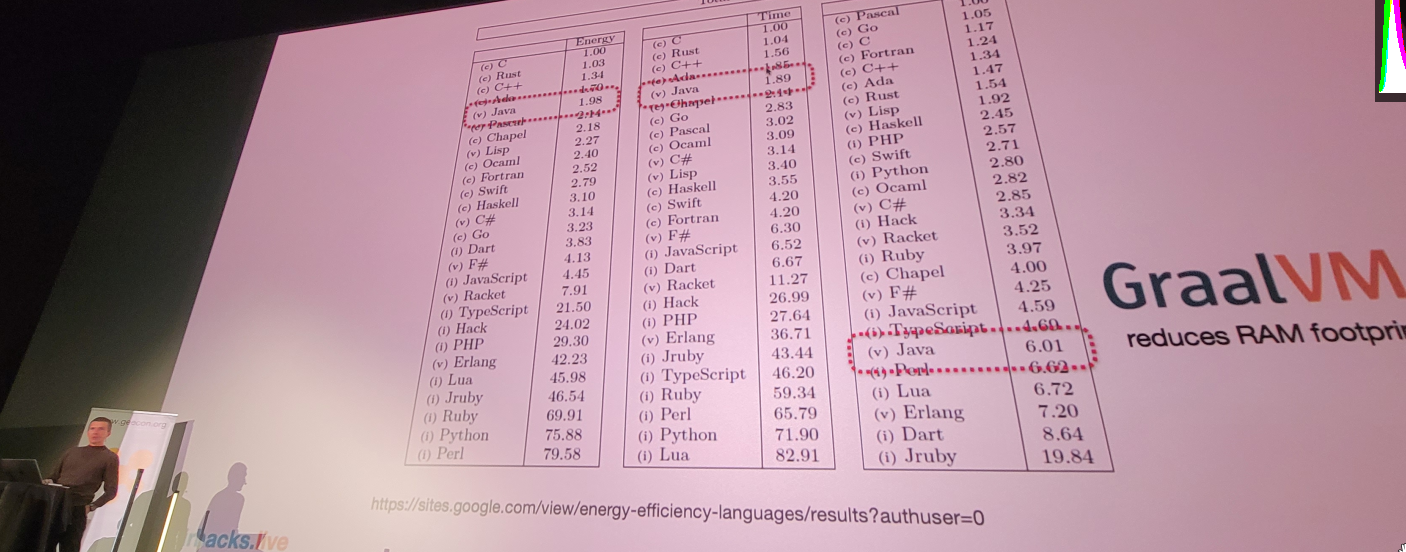
Java’s efficiency has notably improved.
On Crafting Better IDs:
While UUIDs are reliable, they’re not the fastest. Creating a custom solution could be more efficient. UUIDs rely on secrandom, which is often unnecessary and slows down the process.
XUID variations exist that maintain order. If you’re keen on using UTC, consider synchronizing time across services with NTP. A suggestion for EventIds: prefix them with the domain they originate from. To avoid potential issues, implement a processing count to ward off circular flows and employ tracingIds to streamline debugging in microservices.
Moments of Inspiration and Reflection
It felt good seeing Michael Feather’s Talk, as it provided me with a different perspective on trying to TDD with ChatGPT. Also, it was nice to exchange Ideas on the topic.
Tannaz N. Roshandel highlighted the ethical challenges we face in a rapidly changing world in the digital age. I wholeheartedly agree. As we employ AI for sophisticated classification and recommendation, we amplify division. Can we harness AI to counteract this?
Overall, the technological landscape is constantly evolving and increasing in its complexity, overshadowing what is essential. To break the cycle of creating messes, we must shift our focus on the fundamentals. However, I’ve come to see that serverless might be a promising solution.
Meeting Bogo and heading to a pub with him to enjoy some excellent Czech beer was definitely a highlight!
Thanks Bogo! 🍻
More Photos
Bogos Talk.
He smashed his Phone 🤯
Michael Feathers proposed an idea on how to understand code using ChatGPT.
I was recently following an interesting discussion of the Vienna software crafts community with the title: “How to facilitate a conversation between people, where the byproduct is code?”. The discussion is in German and contains interesting ideas about how to code well together, and how to facilitate it.
I tried to give an answer, which got longer and longer.
In the end, I chose to write this blog post which expands upon the original topic of discussion and covers a broader range of related subjects.
I will continue to use the terms
coding together
collaborative coding
Mob Programming, and
Ensemble Programming
interchangeably.
However, when I say coding together or collaborative coding this includes Pair Programming.
When I say Mob Programming or Ensemble Programming I exclude Pair Programming.
By the way: Yes, Mob Programming and Ensemble Programming mean the same thing and may be used interchangeably.
It’s just that the word “Mob” might be associated with something negative, whereas “Ensemble” is a more innocent term.
However, I like to use “Mob” as a verb because it’s so short and simple:
“Let’s mob on this problem!”
“We have been mobbing on this problem.”
Solo Programming Considered Harmful
» A programmer is a person sitting solo in front of their computer, typing rapidly on their keyboard.
A well known stereotype. You have seen the movies.
It turns out that solo programming may not be as good as we think.
No, I’m serious.
I think we overestimate our programming skills.
We tend to overcomplicate things, and we make a lot of mistakes.
We rarely understand the problem that needs to be solved, and we don’t know our tools well.
We often end up with crufty code that isn’t as simple as it could be.
It doesn’t work and often targets the wrong problem.
But hey, don’t worry about it.
We don’t mean to.
We try hard to live up to expectations.
And we work to the best of our ability.
We’re learning.
It’s just not that easy. 🤷♂️
Coding Together as an Answer
Collaborative coding can greatly improve the situation.
By bringing together multiple people with different skills and perspectives, we can gain a deeper understanding of the problem and develop a better solution.
We can take on different roles and complement each other.
We have more eyes to spot mistakes, and together we know our tools better and know more about valuable techniques and practices.
It’s proven that complex problems can be solved better and faster through collaborative coding.
Working on simple applications, we encounter such hard-to-solve problems every day.
But the best thing about coding together is the amplified learning while having a good time.
» A team coding together remotely.
The Cost of Coding Together
There is a cost, of course, to having many programmers working on the same problem at the same time.
We understand those costs well, I think.
What we do not understand so well, however, are the benefits.
Ultimately, it’s a tradeoff.
Will the benefits outweigh the costs?
So let us talk about the benefits.
The Benefits of Coding Together
Amplified Learning
The most striking advantage, and I cannot emphasise this enough, is the amplification in learning.
We need to learn and get better at what we do, desperately so.
All of us, but especially those of us who are new to it.
There’s a big gap between what you learn in school and what you need to know on the job.
We have to make up for that gap somehow.
The thing that works best in my experience is to work together with the people.
Coding together isn’t only the best way to onboard new people, but it also succeeds amazingly quickly in raising the level of participants and turning them into valuable contributors.
I’ve learned so much myself through programming with other people that I honestly believe the learning effect alone makes up for the cost.
Reduction in Cost for Change
We are used to a trade-off between quality and cost, but it does not work that way with software.
In our business, quality is cheap and cruft is expensive.
💡 Martin Fowler wrote an interesting article on this topic.
Code is a liability, and much of the cost is incurred when we need to change and improve it, which happens from day one.
There is this strange idea that maintenance is something that happens after the project is completed.
Well, that’s not exactly true.
We maintain the code starting with the first day.
It’s a challenge to find the right structure and keep it soft enough to change easily.
It’s also terribly expensive to work on poorly designed legacy code, as we often see in enterprise software today.
The cost of this is insidious because there is usually no awareness of it.
So we should strive for and achieve high internal quality to save maintenance cost.
The internal quality of the code can be greatly increased if many people review and revise the code as it’s written.
Better Software for the User
I have seen this repeatedly: Many minds working on the same problem produce more and better ideas, which simply leads to better solutions.
When I say better, I usually mean simpler.
It’s those moments when the majority chase a suboptimal solution and then one person proposes a better one.
We need to think outside the box.
Different people think in different boxes.
More boxes mean more opportunities.
More opportunities lead to a better outcome for the user.
Reduced Work in Progress
We know that high work in progress causes slow down.
When we work together on one problem, it’s also the only problem we work on.
All the people needed to solve the problem are there when they’re needed.
And then, once we’ve taken all the necessary action, it’s done.
It’s off the table.
We can focus entirely on the next problem.
No juggling of tasks.
No waiting around.
No context switching.
Fewer things to keep everyone busy.
Better and easier focus.
A clean one-piece flow.
Having a Good Time
For many people, it can be rewarding to work in a mob with other people, especially if they’re more experienced.
When working on software, we’re often thrown in at the deep end.
Teamwork reduces the stress involved in this.
It’s also more enjoyable for many.
Coding together is a great team-building activity because we work as an actual team.
It may feel awkward at first, but once you get the hang of it, it can be a lot of fun.
Mob Programming is Not Easy
Coding together is challenging.
It’s not simply a matter of one person typing while others observe in silence.
In order to make it work, it’s important for all team members to actively engage and collaborate.
This enables us to utilize all of our minds and build the shared understanding we strive for.
Also, we want to reach a flow state and make continuous progress.
Mob Programming, thus working as an actual team, is a deliberate practice.
Shared Understanding
It’s important to ensure that everyone is on the same page and no one is left behind.
This requires patience, effective communication, and a willingness to listen and explain ideas.
Communication is a challenge, but a skill we can improve with practice.
Speak slowly and use simple language.
Use metaphors and pick people up where they are.
When starting out with a new ensemble, it’s common to feel slow at first.
This is normal as the ensemble gets to know each other and establishes a shared understanding.
After some time you should experience a boost in productivity.
The duration of this initial phase can vary, it could be as short as a few minutes or as long as an hour.
So, it’s all About Human Interaction
Treat each other with kindness, consideration and respect1.
Make people feel safe to contribute, and welcome all forms of contribution, including questions.
Reward a contribution, especially if it makes the person feel unsure.
It is perfectly fine not to know something or not to “get it”.
Be a hero and ask the first question to make others feel confident as well.
Be open to examining and evaluating potentially disruptive ideas, even if they come up suddenly.
Creating a supportive environment that encourages people to contribute will help ensure that the best ideas and insights from all team members are incorporated into the code.
It seems like social skills are the name of the game.
Has programming been the easy part all along?
Agree on a Shared Goal
With many different ideas being shared, it can be difficult for a team to agree on a common goal.
This is another team skill to master.
It’s important to be open to taking a step back and trying someone else’s idea.
It’s okay to try multiple approaches and see which one works best.
By being open to different ideas and perspectives, a team can learn and grow together.
Knowing when to Speak
It’s important for everyone to feel comfortable speaking their mind and sharing their ideas.
However, it’s also important to know when to hold back and listen to others.
One way to deal with this is to keep a private backlog of ideas that come to mind but may not be relevant at the moment.
This can help keep you focused on the task at hand while recording and considering other ideas for later.
Knowing when to speak up and when to hold back is an important skill for effective collaboration.
Bias to Action
In a group, it’s sometimes easy to get stuck in a discussion that goes on forever without trying anything.
Most of the time, it’s less stressful to just try.
Some discussions just are not worth it.
If you notice people talking for several minutes without writing any code, alarm bells should be ringing.
For example, if people are puzzling over the behavior of a particular code for an extended period of time.
It’s time to call to action and suggest that you simply run the code and see.
Distributing Roles
A logical first step is to distribute participants by what they do.
Someone has to type the code, of course.
A common name for this role is Driver, as in the Driver/Navigator relationship of Strong Style Pairing.
I often find that people confuse the names of these two roles, so I prefer to call them “Typist” and “Talker” instead.
May also use “Typing” and “Talking”.
The Role of the Typist
We do not want the Typist to just hack away.
If they did, other participants could merely descipher the then buggy code and make incorrect assumptions.
That’s not sustainable.
We want the Typist to follow the team’s instructions instead.
Being a Typist is hard.
They may get overwhelmed with conflicting ideas.
What should they focus on?
We can solve this problem by using a designated Talker.
It’s not the only person who speaks, but they act as the primary input channel for the Typist, filtering all the ideas and making the final decision.
Even if many things are said, the Typist then knows which voice to focus on.
A Typist Translates
It is a common misconception that the Typist foolishly types out the code they’ve been told to type, word by word, character by character.
Actually, the Typist must make many considerations and decisions.
For example: They may choose to run the tests whenever.
They translate the Talker’s intention into code so that the Talker can stay at the level of their thinking.
The Typist takes care of the details.
That takes a big burden off the Talker.
I mean, typing in itself is quite a challenge.
To know your tools well and being good at typing is an art.
If you are then able to translate the high level intent on top of that, that’s icing on the cake.
Typist Wrapups
One technique I learned at the Python Approvals Mob that improves feedback and shared understanding is Typist wrapups.
It means that a Typist gives a brief explanation of what just happened and what they did after each round.
When a Typist explains this in their own words, misunderstandings are more likely to be uncovered and cleared up.
Being a Talker is not Easy Either
So the Talker is the person who programmes.
The Typist acts as a kind of intelligent input device for them.
A Talker should communicate their thinking.
In other words, they should think out loud.
There are many stages of thinking that we go through.
First, we orient ourselves to the current situation - the context.
Second, we imagine where we want to go from here - a direction.
Third, we formulate a concrete intention - still at a high level.
This is already what a Typist could work with.
Each thought step is shared with the team.
Only then, if needed, do we move on to low-level details: What code to write on what line, syntax, code formatting, keys to use, buttons to click, etc.
The Talker instructs the Typist at the level at which they can operate on, the higher, the better.
Kind of like inverted limbo: How high can you get?
Contributing while not Talking nor Typing
Not being any of those roles doesn’t mean you’re not contributing.
You may step out of the mob for a minute, but what you rather want is to be creative in supporting the group.
Do some research when an opportunity arises.
Ask, if you don’t understand something.
Remind people about the protocol if necessary.
Think ahead and take notes about things we should take care of.
Review the code as it is being typed.
Observe how the group behaves and what they are doing.
Maybe you have an Idea of something the group should be trying that could work well, bring that up.
Note down things that worked well so you can bring it up in the retro.
Rotation
Everyone should get to type and talk.
This keeps everybody engaged.
When deciding on the rotation interval, consider how long it would take for the same person to become a Typist again.
Waiting an hour to go back to typing is probably too much.
It’s hard to maintain attention that long.
A rotation every 2 or 3 minutes works very well with an experienced mob, but you need to be able to do it swiftly.
Work hard to shorten your rotation time.
Rotation time is the time between the start of a rotation and the next Typist/Talker being able to continue.
The perfect rotation time is 0.
Rotations Need Trust
Ending your turn thus giving up control can be difficult.
As a Talker, you not only want to maintain the direction of the previous Talker, but you must trust the next Talker to do the same.
Trust them to continue the idea you have been working on.
Without trust, rotations get bogged down, which hinders the flow.
Hard Rotations vs “Finish Your Thought”
When the timer sounds, you have the option to do a hard rotation, where work stops immediately and team members rotate positions.
Another option is to take some time and finish your current thought, known as “Finish Your Thought” (FYT).
FYT is useful for completing something small or finishing a line of code.
However, when it takes too long, it can disrupt the flow of the team.
People might forget or even ignore that the timer rang at all.
Based on my experience, in those cases, it’s better to do a hard rotation.
Trust in the next person to pick up where you left off and continue the team’s intent.
Calling out your Role
Another common practice that helps maintain flow is when everybody calls out their role when the rotation starts.
It’s practical to also have the person that will be participating in the following rotation to call that out as being “next”.
This avoids misunderstandings and it makes sure that the “next” person is increasing their attention towards being able and continue the given work.
An example would be:
Alice: “I’m Alice, and I’m talking!”
Peter: “I’m Peter, and I’m typing!”
Sarah: “I’m Sarah, and I’m next!”
Find out what Works for Your Mob
As mentioned earlier, Mob Programming is a deliberate practice.
You want to constantly improve the way you work together.
There are no pre-existing rules or frameworks for this.
You need to find your own working agreements.
Regular retrospectives are key in this regard.
Conduct them at least daily.
A two-hour Mob Programming session can lead to a three-hour retrospective, which is great.
The learning effect can be tremendous.
But they don’t have to be that long.
Make them short, maybe a few minutes, but regular.
Use them to find out what worked well for you, and put that in the spotlight.
Turn up the good.
Stay innovative and figure out what you’d like to try.
Retrospectives are about learning and about change.
Use it, act on its results.
Facilitating a Mob Programming
Above all, remind the participants to be patient and treat each other with kindness, consideration, and respect1.
Be a role model in the way you treat them.
People new to Mob Programming will be overwhelmed just by the conviviality of this way of working.
Suddenly they have to pitch their ideas to other people.
They are also not used to being exposed while typing code.
It will take some time for them to get used to this way of working and still have some room in their head to keep a protocol intact.
So you want the initial protocol to be minimalist, and you want to guide it.
Too many rules would throw them off the rails.
Tip: When you notice someone being distracted, offer a short break.
Guide your Protocol
There is a fine line between telling everyone what to do all the time and letting them off the hook.
In the beginning, they won’t remember how to follow your protocol.
It’s just too much.
So you should guide them and kindly tell them what to do and when.
But you also don’t want to fall into the trap of doing everything for them.
Your goal is for the team to be able to take care of themselves and for you to become redundant.
Therefore, every time before you remind them, you should also give them some time to follow the protocol themselves.
Once you become redundant, you may consider joining the mob.
Tip: Do not join a fresh ensemble as a facilitator unless you are very experienced in this.
Facilitation can be complicated, therefor you do not want to particiate in the programming at first.
Stay out of the ensemble and focus on having them work well together.
Keep Time for a Retrospective
You want to end a Mob Programming session with a retro.
Give them the chance to express their feelings about what happened, and share it with each other.
They probably enjoyed it.
Also, they have probably learned new things in the progress.
Microretro
A minimal but nice format for a retro is a microretro.
It only takes a few minutes and you could do it at least once a day.
In this retro, ask these questions:
How did that feel?
What worked well?
The aim of this question is to highlight the positive aspects and achievements.
We want to celebrate what went well and strive to replicate it in the future.
It’s easy to get caught up in dwelling on negative aspects, but this can lead to a negative mindset and impact the overall well-being of the team.
Therefore, this retro focuses on shifting the perspective entirely towards the positive.
Do you have an idea you would like to try?
The goal of this question is to foster experimentation and innovation.
Tools for Mob Programming
mob.sh is a commandline tool and git wrapper to easily hand over code in a remote mob programming.
mobti.me is an online mob timer, and the best that I know.
gitpod is a webapp that is basically vscode in the browser that works well for collaboration as you can share your workspace with others.
remdev on azure is a script to easily boot up a virtual machine on azure for remote mob programming.
cyber-dojo is a brilliant webapp to practice mob programming on a kata. All you need is a browser.
tmate allows you to share your terminal with others to collaborate.
Public Mobs
If you want to try Mob Programming you may choose an existing community.
MobRPG Mob is a weekly public remote mob on thursdays where we develop a webapp for the mob programming rpg. Read the Contribute section to find out how to join (It’s dead simple as in “just show up”).
I recently felt the urge to experiment with my TDD workflow and improve it.
It had too many manual steps, like running the tests, starting a commit, writing a commit message, pulling changes, and pushing it.
It felt boring and wasteful.
I want to automate this stuff and eliminate all the waste.
We’re not aiming high enough with the continuous part in CI/CD. “Integrate at least daily” … Come on! “Hourly” … We can do better than this. “Short-lived Feature Branches” … You got to be kidding. It’s rather “short-lived lies”.
None of this is continuous.
We need to get better and decrease the risk even further.
I want to integrate actually continuously.
I came up with a way that drastically increased my commit frequency.
I managed to create 63 commits in just 25 minutes practicing this way, where I peaked at 6 commits per minute.
Yes, it was just a kata, but that’s not the important part.
On many occasions literally every keystroke went live, and it was all working - covered by tests.
What I did is based on the following requirements:
No manual saving. The code saves itself automatically.
No manual test running. The tests run continuously. They restart automatically as soon as the code changes. And they are fast.
No manual commits. The code is committed automatically whenever the tests pass.
No manual pulling. Changes are pulled automatically before the tests run.
No manual pushing. Every commit is automatically pushed right away.
Not that hard to achieve actually.
Just need proper tooling and a little bit of scripting.
The language I’m trying this with is Java.
The right tools for the job
Since I use IntelliJ, which is a great, maybe the best IDE (*cough* it became a little buggy as of recent *cough*), it saves my code automatically.
So that problem is already solved.
For the continuous running of the tests, I know a few options.
IntelliJ offers a way to trigger the tests automatically, but it’s rather slow.
Then there is this old-school plugin infinitest, but I need something for the CLI so I am able to script it.
And it should be really fast. Incremental compilation would be key. Gradle has it, and it is quite fast.
With Gradle, I could also make the test report pretty using this test-logger plugin.
I like that!
Another option would be the quarkus continuous test runner, which is fairly new, and its test report is so ugly.
Also, I have no idea how to customize, or script it.
So I am going with Gradle for now.
On top of the incremental compilation, Gradle ships with a continuous test runner in:
> gradle -ttest
But since I need more control I chose to use a little helper tool called watchexec instead.
It watches for file changes and then executes a command.
Like this:
> watchexec -e java ./gradlew test
I made some tests and it is just as fast as the Gradle continuous test runner.
If you’d like even more control and a more complicated script, you could also use inotifywait.
However, I like to keep it as simple as possible.
Next, I needed to commit as soon as the tests pass.
A simple bash script would do, but I like to use a modern task runner for the job.
I settled with just.
In case you did not know, it is a modern version of Make.
And it is written in rust for whoever that may concern.
The way this works is you just create a justfile and specify your tasks in it.
The commit command looks like this.
commit:
@git add .
-@git commit -am"wip"
Simple and concise.
To execute it you run:
> just commit
And I do not even have to remember.
My shell courteously suggests to me the available commands.
The @ means that the command is not printed.
By default just would abort on an error exit code, whereas the - tells it to ignore that and continue.
I need this for the case where the tests pass, but I have not changed anything.
For example when I add something and delete it right away.
Then there would be nothing to commit, and git would throw the error, having just abort the task.
I could also allow the empty commit using the allow-empty flag.
But why allow an empty commit for no reason!?
That would be inventory, wasteful.
So here are the first commands in a justfile.
commit:
@git add .
-@git commit -am"wip"test:
clear
@./gradlew test
test-commit:
just test
just commit
tdd-commit:
watchexec -e java just test-commit
Nice! I like it.
First Try
Now we are able to give it a try.
Small steps.
Run > just tdd-commit in a terminal that stays visible next to the IDE.
Write a very simple failing test; Tests fail. -> The test failure is shown in the terminal immediately.
Make the test pass. -> Nicely formatted test report is shown immediately. Changes commit automatically.
Rename the test method; Tests pass. -> Changes commit automatically.
Add another test; Tests fail. -> I am shown the failure report.
In a first attempt to make it pass I notice I cannot make it as easily. I need a preparatory refactoring first.
So I disable the failing test; Tests pass again. -> Changes commit automatically.
I do the preparatory refactoring; Tests pass. -> Changes commit automatically.
I enable the failing test again; Tests fail. -> I am shown the failure report.
Make it pass this time; Tests pass. -> Changes commit automatically.
Wow, this felt smooth.
During all of this, I had not manually done a single save, test run, or commit.
The terminal was open on the right-hand side of my screen, and I got that feedback immediately, continuously.
A meaningless commit history
Let’s take a look at the resulting git history.
wip
wip
wip
wip
wip
Whoops, that’s not very expressive.
But the commits are so small and pleasant to review.
It’s like a playback of every little step that was taken.
It is the actual history.
Honestly, I think the flow might have more value than the documentation.
Still, I would like to improve on that by sneaking in descriptive empty commits every once in a while.
We are used to writing git messages that describe what we did after we did it.
But for this, I would like to propose a different way.
I want to use a commit message to describe what is next. In other words: What my current goal is.
So let’s add a command to create such descriptive empty commits.
Every time I start working on a new goal, I want to write it to my git history first.
Something like > just goal make rover turn left.
The other commit messages would stay ‘wip’ commits and that’s fine.
One idea would be to use further tooling to decode some of the refactoring commits.
For example: The refactoringinsight plugin.
My commit history would then look something like this:
wip
wip
wip
Goal: make rover turn left
wip
wip
wip
wip
Goal: make rover turn right
But what about Integration?
Lots of small commits on my computer are nice.
But if I work in a team I need to integrate my changes to the mainline, too.
So I want to pull before I run my tests, and I want to push after each commit.
It’s called Continuous Integration for a reason, right?
Let’s add that to the justfile.
integrate:
git pull --rebase
just test
just commit
git push
And I think we’re done.
This is the complete file.
It also contains a TCR task.
goal +MESSAGE:
git pull --rebase
git commit --allow-empty-m"Goal: {{MESSAGE}}"
git push
commit:
@git add .
-@git commit -am"wip"test:
clear
@./gradlew test
integrate:
git pull --rebase
just test
just commit
git push
tdd:
watchexec -e java just test
ci:
watchexec -e java just integrate
revert:
@git reset --hard &> /dev/null
@git clean -df &> /dev/null
@echo -e"\033[0;31m=== REVERTED ==="
tcr:
@just test&& just commit || just revert
Conclusion
Notice how I renamed the tdd-commit task to ci.
Continuous Integration is not only about what the build server is doing, it is primarily about what we do.
Coding with this script feels super smooth.
It is actually continuous.
Also, it was not that complicated to set up.
You can probably do even better.
Imagine remote pair- or mob programming with this.
Hand-overs could not be easier.
You just exchange the screen-sharing while the tests pass.
And that’s it.
Probably some people are already working this way? Let me know!
Two years ago, in 2019, I ran the first Coding Dojo at my company EBCONT.
Corona wasn’t a thing back then, so it happened to be an offline event that lasted 4 hours on a Thursday afternoon.
All the brilliant people came together to practice programming and enjoyed it.
How awesome is that?
A lot has changed since then.
When the pandemic happened, I had to adapt and move it online.
So I decided to make it a regular remote whole-day event.
Luckily I had already collected plenty of experience from my friends at the Vienna Software Crafts Community where we also run Coderetreats.
The EBCONT Coding Dojo turned out to be a small success story.
When I started it, I had approximately ten people join, many of which became regular attendees.
But lately, there was a small hype around the event.
People liked it so much that they came up with the idea to create a Coding Dojo T-Shirt and shoot a group photo with it.
Of course, we did so.
I had 25 employees join in the latest event, and it was a lot of fun.
Again, take a closer look at these sweet t-shirts! :-)
Coding Dojo???
So what is a Coding Dojo, how do I do it, and what can you take away from my experience?
The term Dojo originates in Japan and stands for a training facility where they perform katas,
choreographed patterns of martial art movements designed for practice.
A Coding Dojo is a similar thing.
We just perform coding katas.
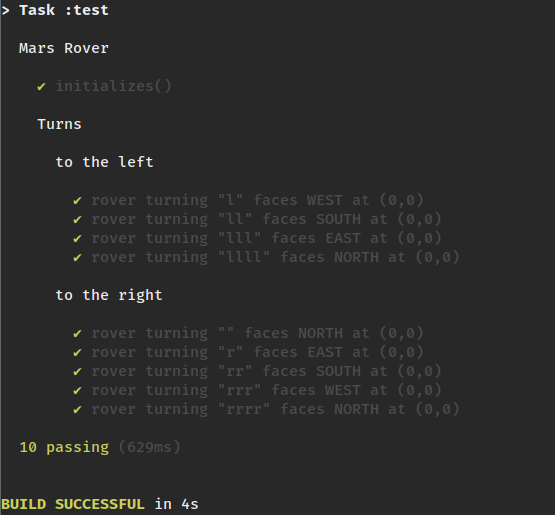
It is a great opportunity to practice technical skills like TDD, design, and refactoring.
Invaluable fundamentals that are mostly not taught in school.
They are left behind the things that turn out to have higher demand: Frameworks and tools.
Under pressure, we naturally fall back to old and maybe poor habits, even though it leads to worse results.
So we take our time to practice and get comfortable with better programming techniques and to be confident to apply them when it counts.
While the traditional Coding Dojo is a short ~2-hour event, the one I do lasts almost a whole day.
The Coding Dojo creates space for developers to practice the fundamentals of programming, away from the pressure of getting things done.
But why not a full day?
An intense full-day practice event can become tiring in my experience.
Closing just a little bit sooner leaves everybody more energy for the final retrospective and the evening after the event.
There are similar whole-day events in the name of Coderetreat and Mobretreat.
The classical Coderetreat has the notion of throwing away your code after a timeboxed session and starting from scratch with a different pair.
So you don’t finish, but get to see many different perspectives within a short time - quite intense.
That’s a little different from what I do.
I like to provide the participants the opportunity to dive deeper into a kata.
So we stay within the same teams and kata throughout the day.
This reduces the relative amount of setup time, which allows us to get more coding done.
The Dojo plan
I decide on the topic and kata in advance, taking the attendees’ skill levels into account.
Before the event, I send them information about what we’ll be working on.
The Dojo starts with a short welcome where we have a few minutes of small talk before the intro session begins.
In the intro session, we discuss the topic and kata.
I like to walk over a minimum of the theory that I believe everybody should know.
One effective way to do this is to keep asking questions so they provide the answers themselves.
At the end of the intro session, we form the teams whose be working together in the following coding sessions.
Balancing teams
I want less experienced people to learn from more experienced people.
But that doesn’t mean more experienced ones won’t learn.
They deepen their understanding as they communicate their ideas.
Curious participants may even challenge their thinking and help them to refresh or even reset.
So I like to balance the skill levels among the teams while also taking into account their desired programming language.
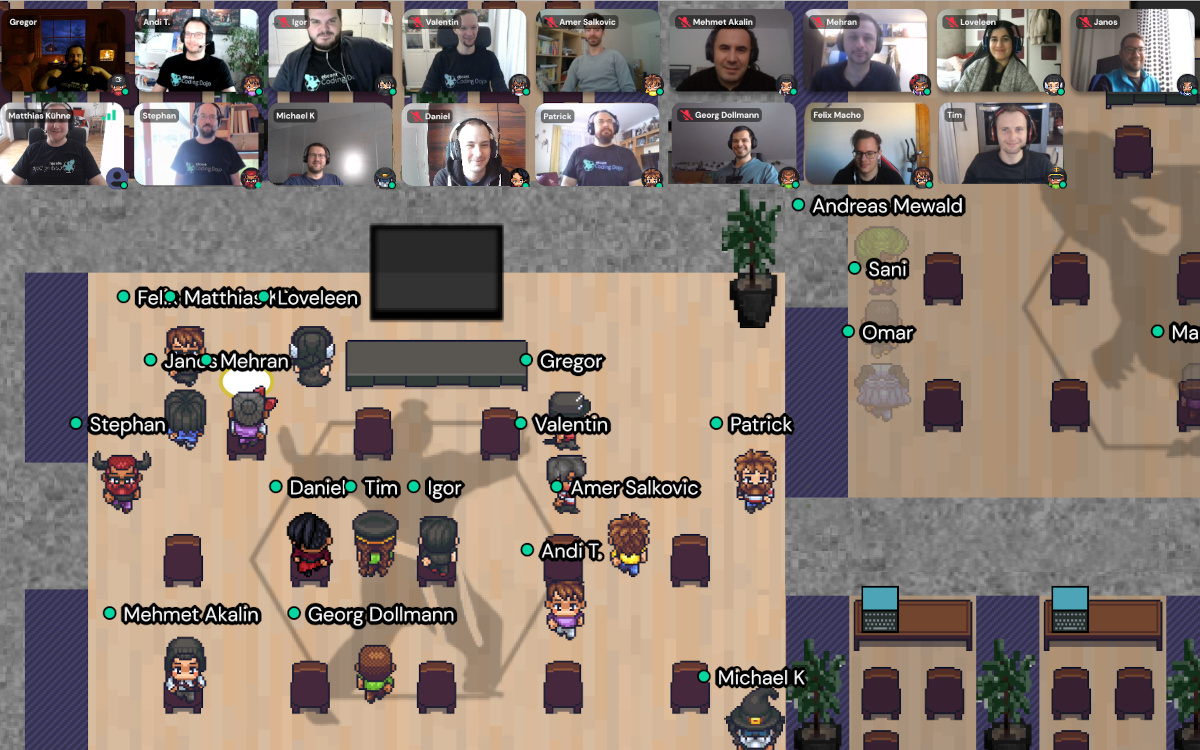
The tool I use Gather-Town helps me with that.
Gather-Town is a remote video conference tool that works like a multiplayer version of Zelda.
You can move around on a 2d map and talk to people in your vicinity.
It creates that feeling of meeting somebody at a conference in the hallway again, just online.
And it allows us to split up and go to different rooms.
Also, it gives me the freedom to customize the map.
I use an altered version of a map that Christian Haas once made for Viennas Global Day of Coderetreat.
I ask the people to assess their abilities and to take a position in the room that matches their confidence to work on the given kata.
Standing on the right end of the room means “very confident” and the left end means “I’m lost”.
The rest of the spectrum is in between.
This creates an overview that makes it fairly easy to form balanced teams.
In my opinion, the optimal team size is 3, but 4 works too.
For bigger teams, you might want to assign a designated facilitator.
Tip: Assign a facilitator for a team
It is not possible for me as a single person to facilitate the programming in every team.
Especially when the people are not used to collaborative coding it makes sense to assign a designated facilitator.
The responsibility of this person is to provide just enough guidance for the team to work well together.
This can be anyone who knows a bit of mob programming.
The role can be rotated so that everybody gets the chance to contribute.
When the team is small and most people are already used to this, a facilitator might not be necessary.
Coding sessions & retrospectives
Typically we manage to have three coding sessions, each of which is followed by a short retrospective.
In these retros, we discuss anything interesting.
How we feel, what we discovered and learned, and how we approached the exercise.
We might also share and review the code we had written so far.
The first session always includes setup, which is the time spent until the team starts coding together in some way.
Somehow, setup always takes a fair amount of time - regardless of how well prepared you are.
The goal is to minimize this time and maximize coding time.
There are lots of ways to code together quickly, and you probably already have some in mind.
However, I would like to share some ways with you I found work well.
#1 Single Driver Mode
A way to get to code quickly is to have just a single person who already has a setup prepared to share their screen.
The downside of this is the risk of other people falling behind due to inactivity.
The avoid that, the person sharing should behave as a passive driver while the other people make decisions and rotate the navigator role.
I prefer when everybody gets to drive, but this usually takes more setup time.
#2 Cyber-Dojo
Cyber-Dojo.org works well for TDD katas, as it allows you to create and share a browser-based setup for any language in no time.
However, it won’t provide you with all the conveniences your IDE does.
Things like continuous compilation, autocompletion, automated refactoring, and so on are not available.
#3 Virtual dev environment
Another way to get to code together quickly is to join the same virtual development environment.
It could be a virtual machine running in the cloud where everything is already set up.
People would connect to it through some remote desktop software.
I prepared something like this, where I can spawn an immutable Linux dev system on Azure: Remdev on Azure
A typical schedule
This is what my typical schedule would look like:
08:50 - 09:10 - Welcome
09:10 - 09:40 - Theory, Details
09:40 - 10:50 - First Coding Session
10:50 - 11:00 - Short Break
11:00 - 12:30 - Second Coding Session
12:30 - 13:30 - Lunch Break
13:30 - 14:50 - Third Coding Session
14:50 - 15:30 - Retro
Coding sessions already include 10-20 minutes of retro time.
While it’s not a big deal to be a little late in the schedule, I want to nail the 1-hour lunch break.
This allows people to plan and spend that time with their families.
My role as a facilitator
As a facilitator, I am not there to actively perform katas.
Instead, my job is to make sure that every participant gets the chance to learn and practice.
So I am merely the organizer and enabler.
I watch out that we keep the schedule (which I’m terrible at) and mostly try to get out of the peoples’ way.
Also, I’m there to help the participants when they get stuck or have questions.
But this doesn’t mean I’m not learning.
Quite the opposite is true.
I learn a lot as I get to see amazing ideas, experience new tech, observe sociotechnical patterns, discover and rediscover non-obvious details.
During the coding sessions, I switch from team to team and observe what they’re up to.
This works well with Gather-Town as I can literally walk from room to room.
Occasionally I see things I am concerned with and bring that up.
I try to do this by asking questions, sparking their creativity, and having them come up with their own solutions.
Or I may see something interesting, for example, a pattern emerge that I find worthy of a discussion, so everybody understands.
If you want to learn more about facilitation in this regard I recommend Peters Coderetreat-Facilitation Podcast.
Many of the things I’m doing are things I learned from him.
Choosing a kata/topic
The Coding Dojo should be a place to practice the fundamentals.
The perfect kata is not too hard for the attendees to tackle, is small enough to finish within the event, and is one that you as a facilitator already know well.
But it doesn’t have to be perfect.
As a refactoring exercise, I like the Expense Report Kata which is nice and small.
Or the Order Dispatch Kata which is about Tell don’t ask.
As for TDD katas I liked Snake, Game of Life, or Mars Rover.
But I also did completely different things.
For example, the Elephant Carpaccio Exercise which is about vertical story slicing and iteration.
Selling your Coding Dojo
If you want to start a Coding Dojo at your company, let me tell you that I think that’s awesome!
I’d recommend getting your boss to agree that it will happen during the work-day and that it will be considered work-time.
Missing know-how is a bottleneck in our industry, where the majority have less than five years of experience.
Fresh developers have to learn so many things about their tech, tools, and frameworks these days, that there is little room left for programming fundamentals like TDD and refactoring.
Some of those are mostly not taught in school either.
When people get to practice these, they become better programmers.
They get better at writing code that works, is more maintainable, and more secure, in less time.
What boss wouldn’t want that?
Conclusion
The Coding Dojo is a great and fun way to provide developers with the space they need to get better at their job.
People enjoy learning from one another in a relaxed environment like this.
I’m proud of the progress participants have made so far at my Dojo.
Feel free to contact me if you have questions, or if you would like to start a similar event.
And if you already have something like this at your company, I would love to hear about that, too.








 » A programmer is a person sitting solo in front of their computer, typing rapidly on their keyboard.
A well known stereotype. You have seen the movies.
» A programmer is a person sitting solo in front of their computer, typing rapidly on their keyboard.
A well known stereotype. You have seen the movies. » A team coding together remotely.
» A team coding together remotely.